

Is your team busy or productive
You can't have both?

Hey this one is long SORRY? If you have 15min to read it I hope you take the time but if not, save it for later when you’re in a meeting you’re not really invested in and see if it helps.

Is Your Team Busy or Productive?
I’m at my in-laws’ place in <redacted> North America, it’s 2am because my body still thinks it’s tomorrow afternoon in Sydney, my ankle has been recovering from a trimalleolar fracture/break and full dislocation for a month now, I’m laying on the floor watching my baby sleep next to me and I’m doing what any reasonable person does when jet-lagged taking care of their baby and unable to sleep: syncing files to my NAS on the other side of the planet.
Look, I had a reason. There were photos. The kid did something cute and the grandparents wanted copies and somehow this turned into “I should just pull down those files I’ve been meaning to organise” which turned into me staring at transfer speeds at 2am while everyone else sleeps.
The connection was surprisingly good. I’d expected the usual transpacific misery, with LEAST DOLLAR cost routing instead of least path cost, but somewhere between my in-laws’ surprisingly decent internet and whatever routing magic was happening across the Pacific, I was getting respectable bandwidth that could saturate my shitty NBN link back home; iperf3 even confirmed!
And yet.
The transfer was crawling.
So I did what any normal person would do: I SSH’d into my home lab from my father-in-law’s guest room and started investigating where my bottleneck actually was.
The Problem With Asking “Am I Max’d Out?”
The first thing I checked was network. Was I actually saturating the link? no. Not even close. The bandwidth was there. The route was clean. The packets were flowing. Send that switch some packets, Switches love packets
Then I remembered.
Right before we left for this trip, I’d replaced a drive in the NAS. One of the eight drives had started throwing SMART warnings, the kind that say “I’m not dead yet but I’m thinking about it” and I swapped it out the night before we flew. After an emergency trip to Centrecom. Responsible typical sysadmin behaviour.
Future Will would thank me. Present Will is LIVID.
The SHR2 array was still rebuilding.
For those fortunate enough to have never experienced this particular joy: SHR2 is Synology’s version of RAID 6. Two drives can fail before you lose data. Very safe. Very sensible - it's a home lab, nothing is sensible. But when you replace a drive, the array has to reticulate splines recalculate parity across all remaining drives and write it to the new one. This involves reading from every other disk and writing to the new one, continuously, for hours or days depending on array size.
Every single file I was trying to sync from North America was competing for disk IO with a rebuild operation that was touching all eight drives simultaneously.
It wasn’t slow because of the Pacific Ocean. It was slow because Past Will had done something responsible and Present Will was paying the price. Stupid Will.
IO Wait - AKA - Looking Busy While Accomplishing Nothing
There’s a concept in computing that’s been stuck in my head since that night. It’s called IO Wait, and it’s when your CPU is technically active and it’s managing requests, maintaining state, checking if data has arrived, but not doing any actual computation.
The utilisation graphs look healthy. The processor looks engaged. But productive throughput? Basically zero. The CPU is just... waiting. Waiting for data to arrive from somewhere slower than itself.
My NAS wasn’t overloaded in any traditional sense. The CPU wasn’t pegged. The RAM was fine. But the disk subsystem was absolutely hammered with eight drives all churning through a parity rebuild while simultaneously trying to serve my file requests and everything was spending more time waiting than working.
I’ve been thinking about that ever since. Specifically, I’ve been thinking about how many teams I’ve worked with that have the same problem.
Everyone looks busy. The calendars are full. Slack is buzzing. People are in meetings, on calls, typing furiously. The utilisation looks great.
But the actual work? It’s queued behind a parity rebuild that nobody remembered was happening.
The Cache Hierarchy
Here’s the thing about my file sync problem the raw speed was there. On paper, this should have been quick.
But “on paper” assumes the data is ready when you ask for it.
Modern CPUs have known about this problem for decades. The processor itself is absurdly fast Billions of operations per second.
AND that speed means nothing if there’s no data to operate on. So chip designers have spent enormous effort building cache hierarchies: L1, L2, L3 each layer a bit further from the CPU core, each a bit slower, each a bit larger.
The whole elaborate architecture exists for one reason: keep data as close as possible to where decisions get made.
I looked up the actual latency numbers for a modern CPU because apparently this is what I do instead of addressing my jet lag and the hierarchy is staggering:

Read that last row again. If reaching into L1 cache is one second of human time, then fetching from an NVMe drive (a fast one), PCIe attached, no spinning rust in sight is waiting nearly a week. A spinning hard drive? You’re waiting until next Spring/or Autumn.
And I had eight spinning hard drives, all of them busy doing something else.
This is why “each Graviton5 core has access to 2.6x more L3 cache than Graviton4, which translates to fewer delays waiting for data and faster application response times.” AWS didn’t just make the cores faster. They moved more data closer.
Meanwhile, I was trying to move data from North America to Sydney a journey of about 150 milliseconds in network terms but the real bottleneck was the spinning rust fighting over parity calculations.
The Organisational Parity Rebuild
I’m back in Sydney now, jet lag mostly resolved, I’m still here with my broken ankle and some sync’d files watching my baby sleep and I keep mapping this onto every team I’ve ever worked with.
The SHR2 rebuild is the perfect a metaphor, actually. It was important work but that necessary background work consumed so many resources that the foreground work, the actual thing I was trying to do, slowed to a crawl.
There’s the “happy” version of this:
The “essential” reorganisation that has everyone updating spreadsheets instead of shipping
The compliance initiative that’s consumed half of everyone’s week for the last month
The tooling migration that seemed important but now has three people in meetings every day
The process improvement that’s somehow made the process take longer
These might all be legitimate and important tasks. But they’re parity rebuilds. They’re consuming IO bandwidth that your actual work needs.
And then there’s the worse version, the sour flavour of organisational IO Wait:
Waiting for approvals that sit in someone’s inbox for three days
Blocked on a decision that requires scheduling a meeting with someone who’s in back-to-back meetings until next Thursday
Needing information that lives in someone’s head, and they’re on holiday
Writing status updates about why nothing has status updates
Architectural meetings where 6 different teams give you requirements and you can’t make a decision but not because of indecision, but because there’s no single threaded owner and you’ve organized into role specific teams instead of product specific teams and the most responsible thing to do is not take accountability for anything more serious than ensuring the next meeting happens so you just design a playbook of 10,000 different patterns hoping someone in the future will see something they like and not bother you.
Platform engineers answering tickets for product, SRE, and SDE(!!) teams because no one really knows how their code works in production because they can’t see it after it goes over the wall.
Everyone is doing something. The individual’s utilisation looks great. But the actual work is queued behind seventeen other requests, waiting for access to a contended resource.
Trust Is Just Pre-Distributed Decision Authority
Let’s go deeper into the metaphor.
You know that decision-making pattern where the SREs, Cloud team, Infrastructure team, Product folks, and SDEs all get in a room a sprawling Slack thread and hash out how to do something? They debate, they whiteboard, they reach consensus. It takes a while but they get there.
Then they take it to the Architecture team, who kick it back with concerns.
So everyone regroups, addresses the concerns, iterates. Gets back to consensus.
Then the CTO has a meeting with their vendor about it and comes back with a completely different direction.
Everyone goes back to their own drawing boards.
I’ve watched this happen so many times. Each handoff is a network round trip. Each escalation is a cache miss that goes all the way to disk. And the latency isn’t just the waiting it’s the context loss. The Architecture team wasn’t in the original conversations. The CTO wasn’t. Each hop loses fidelity, like a game of telephone played through Jira tickets.
Why can’t the person closest to the problem just make the call?
The answer, of course, is trust. Or rather, the absence of it.
Distributed Systems Have Distributed Trust
Think about how distributed computing actually works.
In a properly distributed system, each node has the authority to make local decisions. A replica in ap-southeast-2 doesn’t call home to us-east-1 for permission every time it needs to serve a read. That would be insane. The latency would destroy any benefit of having the replica in the first place.
Instead, you accept some tradeoffs. The ap-southeast-2 replica might serve slightly stale data. It might make a decision that’s locally optimal but not globally optimal. Occasionally, two nodes might make conflicting decisions that need to be reconciled later.
But the system works. It’s fast. It’s resilient. Each node has enough authority (enough trust) to do its job without constantly checking with a central coordinator.
Now think about your org chart.
You’ve got a team of DBAs over here. A team of architects over there. SREs in one silo, cloud specialists in another, product managers somewhere else entirely. When a product team needs to make a decision that touches infrastructure, they don’t have local cache. They have to make a network call to another team. That team has their own queue, their own priorities, their own parity rebuilds happening in the background.
Every decision that crosses a team boundary is a cache miss. And you’ve architected your organisation so that most decisions cross team boundaries.
Embedded Specialists as Local Cache
What if you embedded a DBA in each product team that needs one?
What if instead of a centralised architecture team that reviews everything, you had architects distributed into the teams, with enough trust and authority to make decisions locally?
What if the people closest to the problem had the context and the authority to just... solve it?
This is the organisational equivalent of putting an L1 cache on every core instead of having a single shared cache that everyone has to contend for.
Yes, you lose some economies of scale. Yes, sometimes different teams will make different decisions about similar problems. Yes, you’ll occasionally need to reconcile inconsistencies.
But the latency improvement is massive.
I’ve seen teams go from multi-week decision cycles to same-day decisions just by embedding the right specialist and giving them actual authority. Not “advisory input.” Not “must be consulted.” Actual decision-making power.
The product team with an embedded SRE who can say “yes, that’s fine, ship it” doesn’t have to wait for a ticket to be triaged by the platform team. The squad with an architect who was in the room for all the context doesn’t have to write a six-page document explaining the context to a review board.
Local cache. Local decisions. Local trust.
The Trust Latency Tax
The reason organisations don’t do this? Weirdly is also trust.
“What if they make the wrong decision?”
“What if different teams make inconsistent decisions?”
“What if someone approves something that causes an outage?”
These are legitimate concerns. But they’re also latency taxes. Every layer of review you add, every approval gate, every “just run it past the architects first”that’s a network hop. That’s IO Wait. That’s your team sitting idle while a request traverses the org chart and back.
Every Gate You Add (to the tune of Every Breath You Take)
Every gate you add, Every wait it makes
Every sign-off chase, every form you face
Blocked by IO wait
Every single day - Every board delay
Every ping that’s lost, every week it costs
Lost to IO wait
[Bridge]
Since it’s filed, your context fades without a trace
Weeks go by, the board won’t recognize your case
You ping the chat but help is what you can’t replace
The backlog grows, you long to ship at any pace
Keep waiting, blocking, queueing, please!
And here’s the thing about centralised decision-making: it doesn’t actually prevent bad decisions. It just makes them slower. The Architecture team isn’t magic. They don’t have context your team doesn’t have. Often they have less context, because they weren’t in the room when the tradeoffs were discussed.
What centralised review actually provides is diffusion of responsibility. If the decision goes wrong, well, it was approved by Architecture. It went through the process. Nobody’s individually accountable because everybody was involved.
But that’s not trust. That’s the opposite of trust. That’s a system designed around the assumption that individuals can’t be trusted, so we need a bureaucratic apparatus to catch their mistakes.
In distributed systems terms, you’ve built a system that requires synchronous consensus for every write operation. It’s “safe.” It’s also so slow that nothing ever ships.
Where have I seen that system before? Oh right, you know about CAP Theorem?
CAP Theorem, But For Organisations
There’s a famous theorem in distributed systems called CAP: you can have Consistency, Availability, and Partition tolerance, but you can’t have all three. You have to pick two.(and if you don’t pick…)
Organizations have a similar tradeoff that nobody talks about.
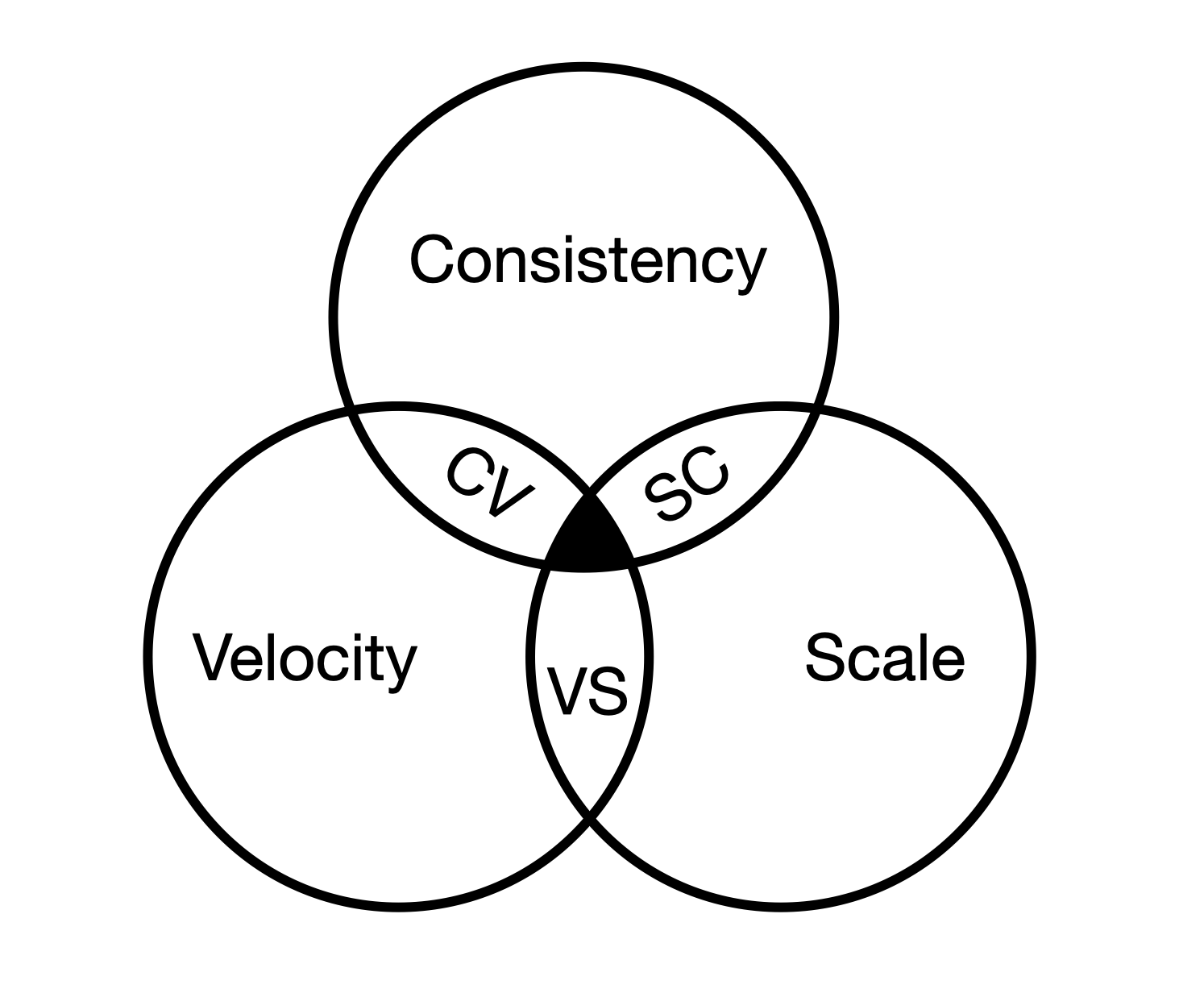
You can have:
Consistency: Every team makes the same decisions the same way. Strong central governance. Architectural purity.
Velocity: Decisions happen quickly. Teams ship fast. Low latency between idea and execution.
Scale: Lots of teams working on lots of things. Big organisation. Many concurrent efforts.
Pick two.
If you want Consistency and Scale, you need massive coordination overhead. Your Architecture team becomes a bottleneck. Everything queues. Velocity becomes a joke.
If you want Consistency and Velocity, you need to stay small. One team, one decision-maker, no handoffs. Works great until you need to scale.
If you want Velocity and Scale, you have to relax Consistency. You MUST accept that different teams will make different decisions. You have to trust the people closest to the problem to make reasonable calls, even if those calls aren’t globally optimal.
Most organizations say they want all three and then build structures that prioritize Consistency above all else. They put every decision through a centralised review process, wonder why nothing ships, and blame the individual teams for being slow.
The teams aren’t slow. The architecture is slow. You’ve built a system where every write has to achieve global consensus, and you’re surprised that writes are expensive? Take a step back, down or out. (just don’t break your ankle like me ok)
Build Better Cache Layers
The fix for my file sync was just... waiting. The rebuild finished eventually, the drives stopped thrashing, and subsequent syncs ran at proper speed. Sometimes you just have to let the parity rebuild complete. I picked Consistency and scale and I had ran out of scale.
But for teams, you have more options. You can think about where knowledge and authority actually live, and whether you’ve accidentally put everything on the slowest tier:
L1 Cache (instant): What can your team decide without asking anyone? What knowledge do they carry in their heads? What authority do they actually have? Every time someone has to send a Slack message and wait for a response, you’ve blown past L1.
L2 Cache (seconds): Documentation. Runbooks. Prior decisions written down somewhere findable. “How did we handle this last time?” shouldn’t require archaeology or a meeting with someone who was there.
L3 Cache (minutes): Shared team knowledge. The embedded specialist who has context and authority. The architect in the room, not the architecture review board three weeks from now.
RAM (acceptable delay): Input that genuinely requires synchronous communication. A meeting, but a short one. A decision that actually needs discussion because it’s genuinely novel.
Disk (danger zone): Multi-week approval processes. Information locked in someone’s head. Decisions requiring escalation through four layers of management. Centralised review boards with six-week backlogs. The CTO’s meeting with AWS.
Every time work travels from L1 to “disk,” you’re introducing months of latency for your team. The work might eventually complete. But at what cost in waiting?
The Metric That Actually Matters
What are you actually measuring when you say that your team is successful?
Most places measure load. Tickets in progress. Story points committed. Utilisation rates. Calendar density. Some even measure “engagement”whatever that means or count the number of pull requests opened.
These are all load metrics and load is one of the most misunderstood concepts in computing.
On a Linux system, there’s a number called “load average” that you’ll see if you run uptime or top. Three numbers, representing the average over 1, 5, and 15 minutes. People see these numbers and think they’re measuring CPU utilisation. They’re not

Load average counts processes in two states: those actively running on a CPU, and those waiting. Waiting to run. Waiting for IO. Waiting for a disk that’s busy rebuilding parity because Past You made a responsible decision three days ago.
A system with a load average of an “8” on a 4-core machine isn’t necessarily doing twice the work it can handle. It might have 7 processes sitting in IO Wait while one process actually runs. The load looks terrible. The CPU is basically idle. Everything is just... waiting for data.
You can have a load average through the roof and almost zero useful throughput.
I’ve seen teams that operate exactly like this.
A team with packed calendars, high “engagement” metrics, and stalled projects is the same thing. Everyone is working. Nobody is shipping. And somewhere in the background, there’s a parity rebuild that nobody remembered to mention or a decision traversing six teams on its way to someone with authority.
The question isn’t “Is everyone busy?”
It’s “Is the productive work actually executing, or is it waiting for data to arrive from somewhere else?”
“Do the people closest to the problem have the trust and authority to actually solve it? Or do they have to make a network call to someone who wasn’t in the room?”
I did briefly consider pausing the rebuild to prioritise my sync. You can do that, technically. But then I imagined explaining to my wife that I’d lost all our family photos because I was impatient at 2am and I decided that some latency is acceptable.
Sometimes the background work really is important. Sometimes you have to let the parity rebuild finish. Sometimes the Architecture review board genuinely needs to weigh in because the decision has organisation-wide implications.
The trick is knowing the difference. Knowing which decisions need global consensus and which ones can be made locally. Knowing when you’re adding safety and when you’re just adding latency. Knowing whether your org chart is an efficient distributed system or a bureaucratic apparatus that requires seventeen approvals to change a DNS record.